











Создание системы, способной обрабатывать миллионы пользователей, требует больше, чем мощное оборудование или эффективный код. Основа лежит в структуре данных. Диаграмма сущностей и связей (ERD) — это не просто документация; это чертеж долгосрочного развития вашего приложения. Когда архитекторы проектируют систему с учетом роста, они предвидят будущую нагрузку, сложность взаимосвязей и необходимость целостности данных. Хорошо спроектированная схема предотвращает накопление технического долга ещё до первого коммита.
В этом руководстве рассматривается подход к проектированию диаграмм сущностей и связей специально для масштабируемых сред. Мы рассмотрим теоретические основы, практические компромиссы и структурные паттерны, которые обеспечивают высокую пропускную способность систем без ущерба для согласованности.
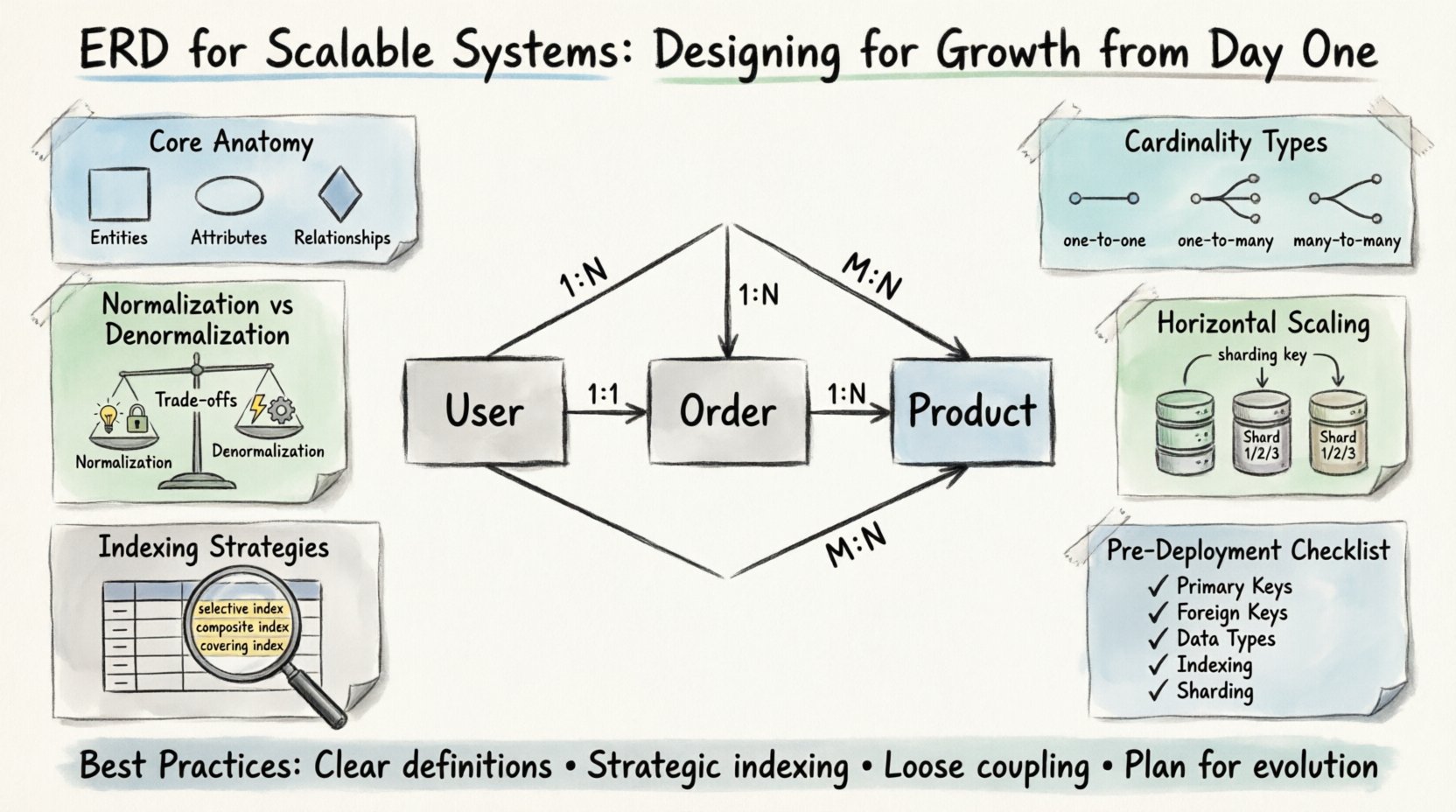
🧩 Основная анатомия масштабируемой ERD
Прежде чем рассматривать масштабируемость, необходимо понять основные строительные блоки. Каждая диаграмма состоит из сущностей, атрибутов и связей. В масштабируемом контексте эти элементы должны быть определены с высокой точностью, чтобы избежать узких мест в будущем.
- Сущности: Они представляют основные объекты вашей бизнес-области. Примеры: Пользователи, Заказы, Товары. В системах с высоким ростом сущности должны быть достаточно детализированы, чтобы позволить независимое масштабирование, но при этом достаточно целостными, чтобы сохранять логические границы.
- Атрибуты: Это свойства, описывающие сущности. Типы данных здесь имеют решающее значение. Правильный выбор типа влияет на эффективность хранения и производительность запросов. Например, использование специального целочисленного типа для идентификаторов предпочтительнее строк для целей индексации.
- Связи: Они определяют, как сущности взаимодействуют между собой. Кардинальность — это наиболее важный аспект, который нужно определить на раннем этапе. Неправильная интерпретация связи один ко многим как многие ко многим может привести к избыточным соединениям и серьезной деградации производительности.
📐 Понимание кардинальности и ограничений
Кардинальность определяет количество экземпляров одной сущности, которые могут или должны быть связаны с экземплярами другой. В масштабируемых системах выбор кардинальности часто определяет, как данные будут разбиваться на части.
- Один к одному (1:1): Редко используется для оптимизации производительности. Часто означает разделение крупной сущности для уменьшения конкуренции за блокировки. Используйте только в тех случаях, когда шаблоны доступа к данным строго различны.
- Один ко многим (1:N): Наиболее распространенная связь. Пользователь имеет много заказов. Эта структура поддерживает эффективную индексацию со стороны внешнего ключа, что позволяет быстро извлекать связанные записи.
- Многие ко многим (M:N): Требует промежуточной таблицы. Хотя гибкая, такая структура может стать узким местом производительности при росте объема данных. При высокой частоте чтения рассмотрите денормализацию или материализованные представления.
При определении ограничений учитывайте накладные расходы на их соблюдение. В распределенных системах строгое соблюдение ограничений внешнего ключа между шардами может привести к задержкам. В таких случаях может потребоваться валидация на уровне приложения, чтобы сохранить пропускную способность системы и целостность данных.
⚖️ Нормализация против компромиссов производительности
Нормализация уменьшает избыточность и повышает целостность данных. Однако системы с высокой производительностью часто требуют отклонения от строгих правил нормализации. Понимание уровней помогает принимать обоснованные решения.
- Первое нормальное состояние (1NF): Атомарные значения. Гарантирует, что каждая ячейка содержит одно значение. Это непреложное условие для реляционной целостности.
- Второе нормальное состояние (2NF): Нет частичной зависимости. Все атрибуты, не являющиеся ключевыми, должны зависеть от всего первичного ключа. Полезно для уменьшения аномалий обновления.
- Третье нормальное состояние (3NF): Нет транзитивной зависимости. Атрибуты, не являющиеся ключевыми, не должны зависеть от других атрибутов, не являющихся ключевыми. Это стандартная цель для большинства транзакционных систем.
Хотя 3NF идеальна для согласованности, она часто требует сложных соединений. В системах с высокой нагрузкой на чтение соединение нескольких таблиц может нагружать движок базы данных. Денормализация предполагает дублирование данных для уменьшения необходимости соединений. Это увеличивает сложность записи, но значительно ускоряет чтение.
📊 Сравнение нормализации и денормализации
| Функция | Нормализовано (3НФ) | Денормализовано |
|---|---|---|
| Целостность данных | Высокая (единый источник правды) | Ниже (требует логики синхронизации) |
| Производительность записи | Быстрее (меньше данных записывается) | Медленнее (избыточные записи) |
| Производительность чтения | Медленнее (требует соединений) | Быстрее (прямой доступ) |
| Использование хранилища | Эффективно | Выше (избыточность) |
| Случай использования | Транзакционные системы (OLTP) | Отчетность и аналитика (OLAP) |
🚀 Проектирование для горизонтального масштабирования
По мере роста объема данных один узел базы данных становится узким местом. Горизонтальное масштабирование предполагает добавление дополнительных узлов для распределения нагрузки. Ваша ERD должна поддерживать эту архитектуру с самого начала.
- Ключи шардирования: Определите столбец, который позволяет равномерно распределить данные по шардам. Этот столбец должен присутствовать в каждом запросе, обращающемся к данным. Если запрос требует сканирования всех шардов, производительность пострадает.
- Внешние ключи между шардами: Объединение таблиц, расположенных на разных шардах, является вычислительно затратным. Минимизируйте межшардовые связи на этапе проектирования. Если связь необходима, рассмотрите возможность кэширования справочных данных.
- Глобальные идентификаторы: Используйте уникальные идентификаторы, которые не зависят от автоинкрементных счетчиков, так как они могут вызывать конкуренцию. Предпочтение следует отдавать UUID или генераторам распределенных идентификаторов.
При моделировании для шардирования учитывайте распределение данных. Пиковые нагрузки возникают, когда один шард получает значительно больше трафика, чем другие. Проанализируйте шаблоны доступа, чтобы убедиться, что ключ шардирования соответствует наиболее часто используемым фильтрам запросов.
📑 Стратегии индексации для больших наборов данных
Индексы необходимы для производительности запросов, но они несут определенные издержки. Каждый индекс потребляет хранилище и замедляет операции записи. Стратегический подход к индексации имеет решающее значение.
- Выборочные индексы: Создавайте индексы для столбцов, которые значительно фильтруют данные. Столбец с низкой кардинальностью (например, пол) часто плохо подходит для первичного индекса.
- Составные индексы: Объедините несколько столбцов в порядке, соответствующем шаблонам запросов. Применяется правило левого префикса, что означает, что первый столбец в индексе должен соответствовать запросу, чтобы индекс мог быть эффективно использован.
- Покрывающие индексы: Включите все столбцы, необходимые для запроса, непосредственно в индексе. Это позволяет базе данных удовлетворить запрос без доступа к данным таблицы, что называется операцией «покрытия».
- Частичные индексы: Индексируйте только подмножество строк таблицы. Это полезно для мягкого удаления или специфических флагов состояния, что уменьшает размер структуры индекса.
Регулярно проверяйте планы выполнения запросов. Индекс, который выглядит хорошо на бумаге, может быть проигнорирован оптимизатором запросов, если статистика устарела. Регулярное обслуживание гарантирует, что движок базы данных принимает оптимальные решения.
🔄 Эволюция и миграции схемы
Системы не являются статичными. Требования меняются, и модель данных должна эволюционировать. Перемещение с версии А на версию Б без простоя — это критически важный навык.
- Добавление изменений: Добавление столбца или таблицы, как правило, безопасно. Оно не нарушает существующие запросы. Это предпочтительный способ внедрения новых функций.
- Операции переименования: Переименование столбца опасно. Это требует обновления кода приложения. Планируйте период устаревания, когда будут поддерживаться как старое, так и новое имя.
- Добавление ограничений: Добавление ограничения (например, NOT NULL) к существующим данным может завершиться неудачей, если данные существуют. Сначала проверьте данные, а затем добавьте ограничение отдельным шагом.
- Обратная совместимость: Убедитесь, что новые версии схемы не нарушают работу существующих клиентов. Используйте флаги функций для включения новой логики только тогда, когда схема будет готова.
🚫 Распространённые ошибки, которые следует избегать
Даже опытные дизайнеры сталкиваются с проблемами. Раннее распознавание этих паттернов может сэкономить значительное время инженерной работы.
- Сильная связанность: Создание отношений, которые вынуждают строго синхронизировать независимые сущности. Держите модули слабо связанными, чтобы обеспечить независимое развертывание.
- Чрезмерная сложность: Проектирование для сценариев, которые могут никогда не произойти. Сосредоточьтесь на 80% случаев использования, которые генерируют 90% трафика. Простота способствует поддержке.
- Пренебрежение мягким удалением: Жесткое удаление удаляет данные навсегда. Для ведения журнала аудита или восстановления используйте флаг состояния (например, is_deleted), а не физическое удаление.
- Проблемы запросов N+1: Не способность предвидеть, как будут извлекаться данные. Планируйте жадную загрузку или пакетную загрузку на уровне доступа к данным, чтобы избежать чрезмерного количества запросов к базе данных.
✅ Чек-лист дизайна перед развертыванием
Перед окончательным утверждением схемы пройдитесь по этому списку проверок, чтобы убедиться в готовности к масштабированию.
- ☐ Первичные ключи: Все таблицы снабжены уникальным проиндексированным первичным ключом?
- ☐ Внешние ключи: Соотношения определены правильно? Точность кардинальности соблюдена?
- ☐ Типы данных: Используются ли числовые типы для идентификаторов и сумм? Стандартизированы ли типы дат?
- ☐ Допустимость значений NULL: Обязательные поля помечены как NOT NULL?
- ☐ Индексация: Проиндексированы ли столбцы, часто используемые в запросах с высокой нагрузкой?
- ☐ Разделение данных (шардинг): Существует ли подходящий ключ шардинга, если предполагается горизонтальное масштабирование?
- ☐ Ограничения: Необходимы ли ограничения для бизнес-логики, или их можно обрабатывать на уровне приложения?
- ☐ Документация: Диаграмма ERD обновлена в соответствии с окончательной реализацией?
🛡️ Целостность данных в распределённых средах
В распределённой среде сложнее обеспечить свойства ACID (атомарность, согласованность, изоляция, устойчивость) на всех узлах. Понимание последствий для вашей диаграммы ERD имеет решающее значение.
- Потенциальная согласованность: Примите, что данные могут временно быть несогласованными между репликами. Проектируйте приложение так, чтобы оно корректно обрабатывало это состояние.
- Идемпотентность: Убедитесь, что операции можно повторно выполнять без побочных эффектов. Это критически важно при сбоях сети, когда запись может быть успешной, но подтверждение потеряно.
- Разрешение конфликтов: Определите, как обрабатывать одновременные обновления одного и того же записи. Временные метки или векторные часы могут помочь определить самую последнюю версию.
Включив эти соображения в ваш диаграмму отношений сущностей, вы создадите систему, которая будет не только функциональной сегодня, но и достаточно надежной для завтрашнего дня. Стоимость изменения схемы в рабочей среде экспоненциально выше, чем правильное проектирование схемы с самого начала.
🔍 Обзор лучших практик
Для повторения: успешное масштабирование зависит от дисциплинированного подхода к моделированию данных. Сосредоточьтесь на четких определениях, соответствующей нормализации и стратегическом индексировании. Избегайте упрощений, которые подрывают целостность данных. Регулярно пересматривайте свои диаграммы по мере развития системы. Статическая ERD — это риск; живая модель — это актив.
Вложите время в этап проектирования. Это окупится снижением затрат на обслуживание и повышением надежности системы. Ваши пользователи никогда не увидят диаграмму, но почувствуют производительность системы, которую она поддерживает.