











एक एंटिटी रिलेशनशिप डायग्राम (ERD) सिर्फ एक ड्राइंग नहीं है। यह आपके डेटा इंफ्रास्ट्रक्चर का ब्लूप्रिंट है। जब इस ब्लूप्रिंट में कमी होती है, तो परिणामस्वरूप प्रणाली में संरचनात्मक कमजोरियाँ आ जाती हैं, जो डेटा विचलन, प्रदर्शन की अवरोध और रखरखाव की दुर्गंध के रूप में प्रकट होती हैं। बहुत से डेवलपर्स एक साफ शुरुआत करते हैं, लेकिन इंप्लीमेंटेशन चरण के दौरान क्रमिक विफलताओं का सामना करते हैं। मूल कारण तकनीकी स्टैक के बजाय डिज़ाइन तर्क के होता है।
एक ERD के विफल होने के कारण को समझने के लिए सरल सिंटैक्स से आगे बढ़ने की आवश्यकता होती है। इसके लिए संबंधों, कार्डिनैलिटी, नॉर्मलाइजेशन और अर्थग्राह्य स्पष्टता का आलोचनात्मक विश्लेषण करने की आवश्यकता होती है। यह गाइड डेटाबेस की अखंडता को कमजोर करने वाली सबसे आम गलतियों का विश्लेषण करता है और बताता है कि उन्हें उत्पादन वातावरण को प्रभावित करने से पहले कैसे पहचाना जाए।
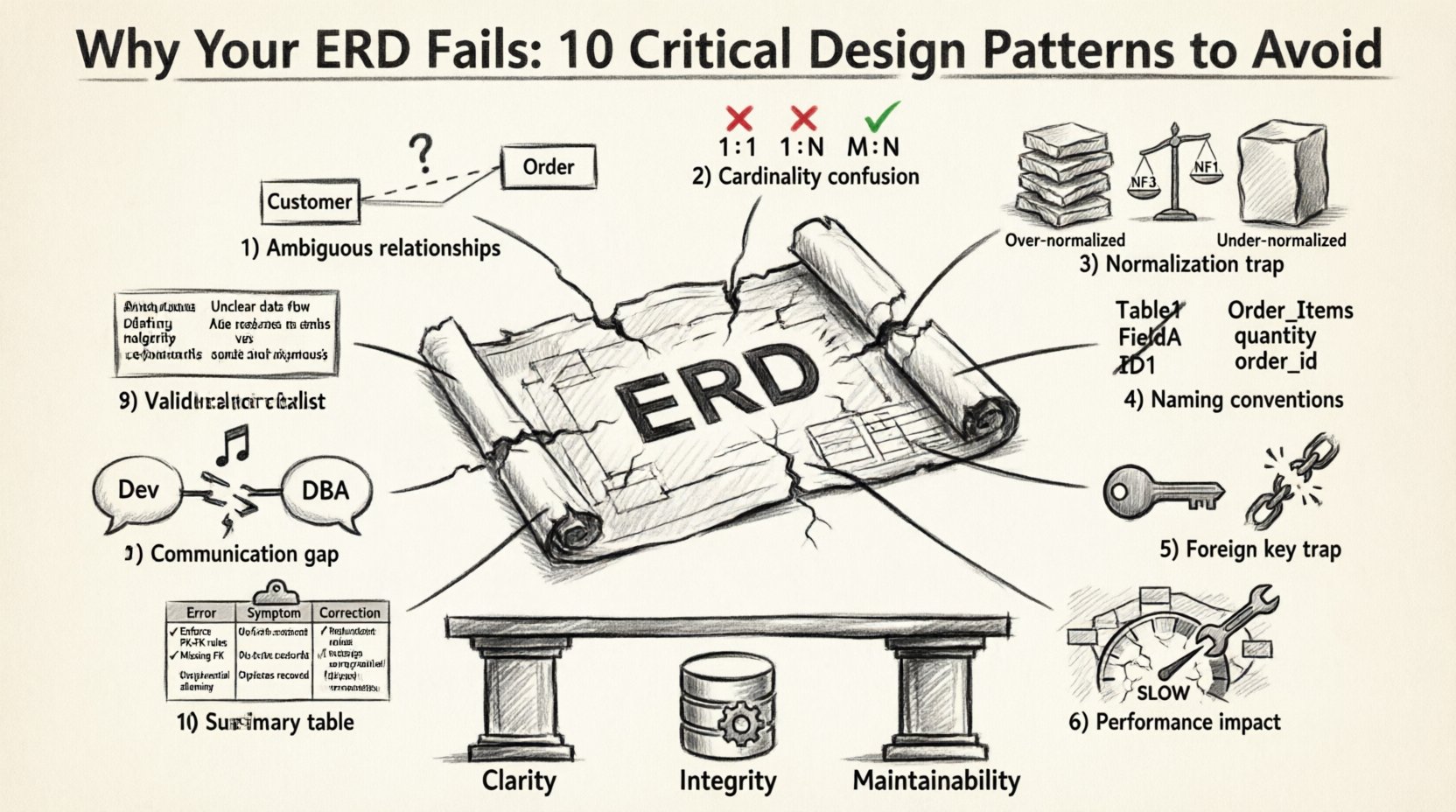
1. संबंधों की अस्पष्टता 🤔
हर ERD के केंद्र में संबंध होता है। यह डेटा एंटिटीज़ के बीच बातचीत को परिभाषित करता है। सबसे अधिक आम विफलता बिंदु अस्पष्टता है। जब कोई संबंध स्पष्ट रूप से परिभाषित नहीं किया जाता है, तो डेटाबेस इंजन को इरादे का अनुमान लगाना पड़ता है, जिसके लिए गलत डेटा संबंध बनने की संभावना होती है।
अप्रत्यक्ष बनाम स्पष्ट संबंध
स्पष्ट संबंध विदेशी कुंजियों और सीमाओं के माध्यम से परिभाषित किए जाते हैं। अप्रत्यक्ष संबंध अनुप्रयोग तर्क पर निर्भर करते हैं जो संगतता बनाए रखते हैं। इस विभाजन के कारण एक खतरनाक दुर्बलता उत्पन्न होती है जिसे कहा जाता हैअखंडता का अंतराल.
- स्पष्ट: डेटाबेस इंजन द्वारा लागू किया जाता है। यदि कोई रिकॉर्ड हटाया जाता है, तो निर्भर रिकॉर्ड को परिभाषित नियमों (कैसकेड, सेट नल) के अनुसार संभाला जाता है।
- अप्रत्यक्ष: कोड द्वारा लागू किया जाता है। यदि कोड विफल हो जाता है या बायपास कर दिया जाता है, तो अनाथ डेटा बना रहता है।
जब आपका डायग्राम स्पष्ट रूप से नहीं चिह्नित करता है कि संबंध के किस पक्ष में विदेशी कुंजी है, तो डेवलपर्स मान्यताएं बनाते हैं। एक टीम शायद कुंजी को टेबल A में रखेगी, जबकि दूसरी टीम इसे टेबल B में रखेगी। इससे चक्रीय निर्भरता और क्वेरी की जटिलता उत्पन्न होती है।
अनुपस्थित कार्डिनैलिटी लेबल
कार्डिनैलिटी के बिना कोई संबंध अनुमान है। कार्डिनैलिटी एक एंटिटी के उन उदाहरणों की सटीक संख्या निर्दिष्ट करती है जो दूसरे एंटिटी के उदाहरणों से संबंधित हो सकते हैं या अनिवार्य हो सकते हैं। इन लेबल्स के बिना:
- क्वेरी ऑप्टिमाइज़र्स को कठिनाई होती है: प्रणाली जॉइन रणनीति को प्रभावी ढंग से निर्धारित नहीं कर सकती है।
- डेटा सत्यापन विफल हो जाता है: नियम जैसेNOT NULLगलत तरीके से लागू किए जाते हैं।
- व्यावसायिक तर्क टूट जाता है: एक “उपयोगकर्ता” को शून्य “आदेश” होने की अनुमति दी जा सकती है जबकि व्यावसायिक नियम एक की आवश्यकता करता है।
2. कार्डिनैलिटी की भ्रम: एक-से-बहुत के फंदे 📉
कार्डिनैलिटी की गलतियाँ सबसे अधिक प्रचलित डिज़ाइन की कमी हैं। वे आमतौर पर मॉडलिंग चरण के दौरान व्यावसायिक नियमों के गलत व्याख्या के कारण होती हैं। एक-से-एक (1:1), एक-से-बहुत (1:N) और बहुत-से-बहुत (M:N) के बीच भ्रम अक्सर उत्पन्न होता है।
1:1 संबंध और अतिरिक्तता
1:1 संबंध को गलत तरीके से मॉडल करने से अनावश्यक अतिरिक्तता उत्पन्न होती है। यदि दो टेबल एक ही प्राथमिक कुंजी साझा करते हैं, तो एक को हटाने या मिलाने के लिए उपयुक्त माना जाता है।
| परिदृश्य | सही पैटर्न | खराब पैटर्न |
|---|---|---|
| कर्मचारी और सुरक्षा बैज | एकल तालिका जिसमें वैकल्पिक स्तंभ हैं | दो तालिकाएँ जो 1:1 से जुड़ी हैं |
| उत्पाद और मूल्य इतिहास | एक तालिका जिसमें समयचिह्न है | दो तालिकाएँ जो 1:1 से जुड़ी हैं |
खराब पैटर्न में, प्रत्येक अद्यतन के लिए दो तालिकाओं को जोड़ने की आवश्यकता होती है। सही पैटर्न में, डेटा सह-स्थित होता है, जिससे I/O संचालन कम होते हैं।
1:N संबंध और विदेशी कुंजियाँ
यह मानक पैटर्न है। हालांकि, विदेशी कुंजी के स्थान का होना महत्वपूर्ण है। विदेशी कुंजी “बहुत” वाली तरफ होती है।
- सही:
आदेशतालिका में समावेश हैउपयोगकर्ता_आईडी. - गलत:
उपयोगकर्तातालिका में सूची हैआदेश_आईडी.
एकल स्तंभ में आईडी की सूची संग्रहीत करना पहले सामान्य रूप (1NF) के उल्लंघन करता है। इससे स्ट्रिंग पार्सिंग या जटिल JSON संभालने के लिए मजबूर किया जाता है, जो प्रदर्शन को खराब करता है और मानक इंडेक्सिंग को रोकता है।
बहुत-से-से-बहुत और संबंधित तत्व
बहुत-से-से-बहुत संबंधों को किसी भी तालिका में एकल विदेशी कुंजी द्वारा नहीं दर्शाया जा सकता है। इन्हें एक संबंधित तत्व (ब्रिज तालिका) की आवश्यकता होती है।
आम विफलता: ब्रिज तालिका को नजरअंदाज करना और दो तालिकाओं को सीधे जोड़ने की कोशिश करना।
यह क्यों विफल होता है: आप संबंध पर विशेषताओं को संग्रहीत करने की क्षमता खो देते हैं। उदाहरण के लिए, एक छात्र और एक पाठ्यक्रम संबंध को एक ग्रेड की आवश्यकता होती है। आप ग्रेड को स्टूडेंट टेबल या कोर्स टेबल में अकेले स्टोर नहीं कर सकते।
3. सामान्यीकरण और असामान्यीकरण की जाल 🧱
सामान्यीकरण डेटा को तार्किक टेबल में व्यवस्थित करके अतिरिक्तता को कम करता है। हालांकि, अत्यधिक सामान्यीकरण प्रदर्शन को मार सकता है। अपर्याप्त सामान्यीकरण अपडेट विचलन बनाता है। संतुलन खोजना एक तकनीकी चुनौती है।
अपडेट विचलन
जब डेटा कई स्थानों पर स्टोर किया जाता है और एकमात्र सत्य का स्रोत नहीं होता है, तो उसे अपडेट करना जोखिम भरा हो जाता है।
- प्रविष्टि विचलन: आप एक रिकॉर्ड नहीं जोड़ सकते क्योंकि आवश्यक विदेशी कुंजी गायब है।
- अपडेट विचलन: एक पंक्ति में मान बदलना लेकिन दूसरी में नहीं बदलना असंगत डेटा के कारण बनता है।
- डिलीट विचलन: एक रिकॉर्ड को गलती से डिलीट करने से उसमें स्टोर महत्वपूर्ण जानकारी भी गायब हो जाती है।
जब असामान्यीकरण करना चाहिए
असामान्यीकरण पढ़ने के प्रदर्शन में सुधार करने के लिए जानबूझकर किया जाने वाला चयन है। इसे डिफ़ॉल्ट स्थिति नहीं होना चाहिए। यह केवल तभी उचित है जब:
- पढ़ने की आवृत्ति लेखन आवृत्ति को बहुत अधिक ओवरव्हेल करती है।
- जॉइन लागतें डेटा के आकार के कारण अत्यधिक हैं।
- रिपोर्टिंग आवश्यकताएं पूर्व-समग्र डेटा की आवश्यकता होती है।
डिज़ाइनर अक्सर बहुत जल्दी असामान्यीकरण कर देते हैं। इससे डेटा ड्रिफ्ट का जोखिम आता है। यदि स्रोत डेटा बदलता है, तो असामान्यीकृत कॉपी को ट्रिगर या एप्लिकेशन लॉजिक के माध्यम से अपडेट किया जाना चाहिए, जिससे जटिलता और संभावित विफलता के बिंदु बढ़ जाते हैं।
4. नामकरण प्रणाली और अर्थविज्ञान 🏷️
एक स्कीमा को लिखने की तुलना में अधिक बार पढ़ा जाता है। यदि नामकरण स्पष्ट नहीं है, तो डेवलपर पर मानसिक भार बढ़ जाता है, जिससे बग आते हैं। अर्थविज्ञान स्पष्टता संरचनात्मक अखंडता के बराबर महत्वपूर्ण है।
सामान्य नाम
जैसे नाम टेबल1, कॉलम_ए, या डेटा कोई संदर्भ नहीं देते हैं। इनके कारण डेवलपर को एप्लिकेशन कोड को देखना पड़ता है ताकि डेटाबेस संरचना को समझ सके।
- बेहतर:
आदेश_आइटम,लेनदेन_तिथि,ग्राहक_प्रोफ़ाइल.
असंगत एकवचन बनाम बहुवचन
कुछ मानकों में एकवचन तालिका नामों को प्राथमिकता दी जाती है, जबकि अन्य में बहुवचन। उनका मिश्रण भ्रम पैदा करता है।
| असंगत | संगत |
|---|---|
उपयोगकर्ता, आदेश, उत्पाद |
उपयोगकर्ता, आदेश, उत्पाद |
संगति के कारण पूर्वानुमानित प्रश्न उत्पन्न करना संभव होता है। असंगति के कारण कोड लेयर में हाथ से मैपिंग की आवश्यकता होती है।
आरक्षित शब्द
जैसे कीवर्ड का उपयोग करना आदेश, उपयोगकर्ता, या समूहतालिका नाम के रूप में उपयोग करने से प्रश्न भाषा में सिंटैक्स त्रुटियां हो सकती हैं। इन पहचानकर्ताओं को अक्सर एस्केप करने वाले अक्षरों की आवश्यकता होती है, जिससे प्रश्नों को पढ़ना और बनाए रखना कठिन हो जाता है।
5. विदेशी कुंजी जाल 🔑
विदेशी कुंजियाँ संबंधात्मक अखंडता की चिपचिपाहट हैं। हालांकि, उन्हें अक्सर गलत सेटअप किया जाता है। इस खंड में कुंजी के कार्यान्वयन के बारीकियों का अध्ययन किया गया है।
स्व-संदर्भित कुंजियाँ
पुनरावृत्ति संबंध, जैसे एककर्मचारीदूसरे को प्रबंधित करने वालाकर्मचारी, उसी तालिका की ओर इशारा करने वाली विदेशी कुंजी की आवश्यकता होती है। यदि प्रतिबंध सही तरीके से सेट नहीं किया गया है, तो आपको अनंत लूप या असंगत वृक्ष नोड्स का खतरा हो सकता है।
- समस्या:उप-कर्मचारियों के साथ निपटे बिना एक प्रबंधक को हटाने की अनुमति देना।
- समाधान:परिभाषित करें
कैसकेडयाNULL सेट करेंप्रतिबंधों को स्पष्ट रूप से परिभाषित करें।
संयुक्त कुंजियाँ
संयुक्त कुंजियाँ (एक प्राथमिक कुंजी के रूप में कार्य करने वाले कई कॉलम) शक्तिशाली हैं लेकिन भारी हैं। यदि एक बच्चा तालिका संयुक्त कुंजी के संदर्भ में है, तो बच्चा तालिका को माता-पिता कुंजी के सभी कॉलम को शामिल करना होगा।
असफलता का तरीका: यदि माता-पिता कुंजी बदल जाती है (उदाहरण के लिए, प्राकृतिक कुंजी अपडेट), तो बच्चा तालिका को कई पंक्तियों में अपडेट करना होगा। यह महंगा है और दौड़ स्थितियों के लिए अधिक संवेदनशील है।
निर्धारित विदेशी कुंजियाँ
एक विदेशी कुंजी कॉलम को केवल तभी निर्धारित किया जाना चाहिए जब संबंध वैकल्पिक हो। यदि संबंध अनिवार्य है, तो कॉलम को होना चाहिएNOT NULL.
चेतावनी:उपयोग करनाNULL“कोई संबंध नहीं” को दर्शाने के लिए कठिनाई पैदा करता है। प्रत्येक प्रश्न को जांचना होगाIS NULLयाNULL नहीं है, जो कुछ डेटाबेस इंजनों में सूचीकरण के उपयोग को रोकता है।
6. खराब डिज़ाइन के प्रदर्शन प्रभाव 🚀
एक खराब डिज़ाइन वाला एरडी केवल डेटा त्रुटियाँ नहीं पैदा करता है; यह प्रदर्शन में गिरावट लाता है। भौतिक भंडारण और प्रश्न निष्पादन योजना तार्किक मॉडल के सीधे परिणाम हैं।
सूचीकरण टूटना
जब विदेशी कुंजियों को सूचीबद्ध नहीं किया जाता है, तो डेटाबेस इंजन तात्विक अखंडता की पुष्टि करने के लिए पूरी टेबल स्कैन करता है। जैसे-जैसे डेटा का आयतन बढ़ता है, यह जॉइन को काफी धीमा कर देता है।
जॉइन की जटिलता
गहन रूप से नेस्टेड संबंधों के लिए बहुत सारे जॉइन की आवश्यकता होती है। प्रत्येक जॉइन को गणनात्मक ओवरहेड जोड़ता है। विश्लेषणात्मक प्रश्नों के लिए एक स्टार स्कीमा डिज़ाइन (एक फैक्ट टेबल के चारों ओर केंद्रित) आमतौर पर एक स्नोफ्लेक स्कीमा (अत्यधिक सामान्यीकृत) से बेहतर होता है।
लॉक प्रतिस्पर्धा
अत्यधिक सामान्यीकृत डिज़ाइन आमतौर पर अपडेट के दौरान संगतता बनाए रखने के लिए अधिक लॉक की आवश्यकता महसूस करते हैं। उच्च समानांतरता वाली प्रणालियों में, इससे ब्लॉकिंग और समय सीमा समाप्त हो जाती है। थोड़ा असामान्य डिज़ाइन प्रति लेनदेन में लॉक किए गए पंक्तियों की संख्या को कम कर सकता है।
7. रखरखाव के रातोंरात के भयंकर सपने 🛠️
खराब एरडी की वास्तविक लागत समय के साथ प्रकट होती है। रखरखाव वह स्थान है जहां सैद्धांतिक कमियाँ व्यावहारिक विफलताओं में बदल जाती हैं।
स्कीमा विकास
जब आवश्यकताएं बदलती हैं, तो एक कठोर स्कीमा बदलने में कठिनाई होती है। एक नई संबंध जोड़ने के लिए टेबल ड्रॉप करना, डेटा माइग्रेट करना और एप्लिकेशन लॉजिक को फिर से लिखना आवश्यक हो सकता है। एक लचीला डिज़ाइन बदलाव की अपेक्षा करता है।
- उदाहरण:पहले अनमॉडेल्ड एक संबंध में एक नया गुण जोड़ना।
- प्रभाव: एक ALTER TABLE बयान की आवश्यकता होती है जो टेबल को घंटों के लिए लॉक करता है।
डेटा स्थानांतरण
अगर लक्षित एरडी स्रोत से मेल नहीं खाता है, तो प्रणालियों के बीच डेटा स्थानांतरण जोखिम भरा होता है। असंगत कार्डिनैलिटी माइग्रेशन प्रक्रिया के दौरान डेटा के नुकसान या दोहराव के लिए मजबूर करती है।
8. प्रमाणीकरण के लिए चेकलिस्ट ✅
एरडी को अंतिम रूप देने से पहले एक व्यवस्थित ऑडिट चलाएं। संभावित डिज़ाइन की कमियों की पहचान करने के लिए इस चेकलिस्ट का उपयोग करें।
- क्या सभी संबंध स्पष्ट रूप से परिभाषित किए गए हैं? अप्रत्यक्ष संबंधों की जांच करें।
- क्या सभी रेखाओं पर कार्डिनैलिटी लेबल की गई है? सुनिश्चित करें कि 1:1, 1:N या M:N स्पष्ट है।
- क्या प्राथमिक कुंजियाँ अद्वितीय और स्थिर हैं? अक्सर बदलने वाली प्राकृतिक कुंजियों से बचें।
- क्या विदेशी कुंजियाँ सूचीबद्ध हैं? जॉइन के लिए प्रदर्शन की पुष्टि करें।
- नॉर्मलाइजेशन उचित है? सुनिश्चित करें कि कोई अपडेट विचलन न हों।
- क्या नामकरण प्रथाएं संगत हैं? एकवचन/बहुवचन के मिश्रण की जांच करें।
- क्या आरक्षित शब्दों से बचा गया है? डेटाबेस की कीवर्ड सूचियों के खिलाफ जांच करें।
- क्या रिकर्सिव संबंधों के लिए कोई योजना है? स्वयं-संदर्भित सीमाओं को परिभाषित करें।
9. मानव कारक: संचार 🗣️
अक्सर, ईआरडी विफलताएं तकनीकी नहीं होतीं; वे संचार विफलताएं होती हैं। आरेख व्यापार स्टेकहोल्डरों और तकनीकी टीम के बीच एक संविदा है।
गायब व्यापार नियम
यदि व्यापार नियम है “एक उपयोगकर्ता के कई पते हो सकते हैं,” लेकिन आरेख में 1:1 संबंध दिखाया गया है, तो डेटा वैध व्यापार परिदृश्यों को अस्वीकार कर देगा। आरेख को व्यापार संचालन की वास्तविकता को दर्शाना चाहिए, केवल वर्तमान डेटाबेस संरचना को नहीं।
स्कीमा के लिए संस्करण नियंत्रण
कोड की तरह, स्कीमा को संस्करण नियंत्रण की आवश्यकता होती है। बदलावों को ट्रैक किए बिना, यह असंभव है कि किसी संबंध को क्यों जोड़ा या हटाया गया था, इसकी जांच की जा सके। इससे “कबीलेदार ज्ञान” की स्थिति बनती है जहां केवल एक व्यक्ति ही डिजाइन को समझता है।
10. महत्वपूर्ण पैटर्न का सारांश 📋
सारांश में, आपके डेटा प्रणाली की अखंडता आपके डिजाइन की सटीकता पर निर्भर करती है। नीचे सामान्य त्रुटियों और उनके सुधारों का संगृहीत दृश्य दिया गया है।
| त्रुटि श्रेणी | लक्षण | सुधार |
|---|---|---|
| गायब कार्डिनैलिटी | अस्पष्ट डेटा सीमाएं | स्पष्ट संबंध लेबल जोड़ें |
| गलत विदेशी कुंजी स्थापना | चक्रीय निर्भरताएं | कुंजी को “बहुत” वाली ओर रखें |
| अत्यधिक नॉर्मलाइजेशन | धीमी प्रश्न, बहुत अधिक जॉइन | रणनीतिक अनॉर्मलाइजेशन |
| अपर्याप्त नॉर्मलाइजेशन | डेटा दोहराव, विचलन | नॉर्मलाइजेशन नियम लागू करें |
| खराब नामकरण | उच्च संज्ञानात्मक भार | स्थिर नामकरण मानकों को अपनाएं |
| आरक्षित शब्द | वाक्य रचना त्रुटियां | एलियास या भागने वाले अक्षरों का उपयोग करें |
11. आत्मविश्वास के साथ आगे बढ़ें 🚀
एक टिकाऊ एंटिटी रिलेशनशिप डायग्राम डिज़ाइन करना एक विषय है जो सिद्धांत और व्यावहारिक सीमाओं के बीच संतुलन बनाता है। इसमें धैर्य, विश्लेषण और डेटा के सिस्टम के माध्यम से प्रवाह के बारे में गहन समझ की आवश्यकता होती है। इस गाइड में चर्चा किए गए सामान्य पैटर्न से बचकर आप एक आधार बनाते हैं जो स्केलेबिलिटी और विश्वसनीयता को समर्थन देता है।
याद रखें, डायग्राम एक जीवंत दस्तावेज है। यह व्यवसाय के विकास के साथ विकसित होता है। नियमित समीक्षा सुनिश्चित करती है कि डिज़ाइन संचालन वास्तविकता के साथ संरेखित रहे। एरडी को एक बार के कार्य के रूप में न लें। इसे अपनी डेटा संपत्ति की मुख्य वास्तुकला के रूप में लें।
स्पष्टता पर ध्यान केंद्रित करें। आंतरिक अखंडता पर ध्यान केंद्रित करें। रखरखाव क्षमता पर ध्यान केंद्रित करें। ये तीन स्तंभ उन विफलताओं को रोकेंगे जो बहुत सी प्रणालियों को प्रभावित करती हैं। जब आप त्वरित कार्यान्वयन की तुलना में डिज़ाइन तर्क को प्राथमिकता देते हैं, तो आप भविष्य में अनगिनत घंटों के डिबगिंग और पुनर्गठन की बचत करते हैं।
अपने संबंधों की पुष्टि करने के लिए समय लें। अपने कुंजियों की जांच करें। अपने नॉर्मलाइजेशन की समीक्षा करें। आप अब निवेश की गई मेहनत बाद में सिस्टम स्थिरता में लाभ के रूप में लौटेगी। एक अच्छी तरह से डिज़ाइन किया गया स्कीमा तब अदृश्य होता है जब यह काम करता है, और तब दिखाई देता है जब यह विफल होता है। उस डिज़ाइन का चयन करें जो काम करता है।